Building Resiliency, A true competitive advantage
TLDR; Resiliency is the capacity to recover quickly from difficulties; toughness.
Businesses are complex systems
When you start out, you have one idea, one simple system that does what you originally set out to do. Then you grow successful, you have more customers, you add more features, you add more reporting capabilities, you add more dependencies inside and outside your company, you add more vendors and use third party services.
Your simple system is not so simple any more. It is a complex system now.
And complex systems fail.
All those vendors, all those dependencies, those interacting systems, those data feeds that power your reports, your machine learning algorithms, those logging capabilities etc etc, each of them add failure vectors to your system.
Your system now has lots of failure modes. And given how many of those exist, you’re probably not even aware of all the little failures that are constantly happening across your system. That is, your system is probably running in a degraded state a lot more than you know. You only notice when the degradation becomes bigger.
The Zeebrugge Ferry accident

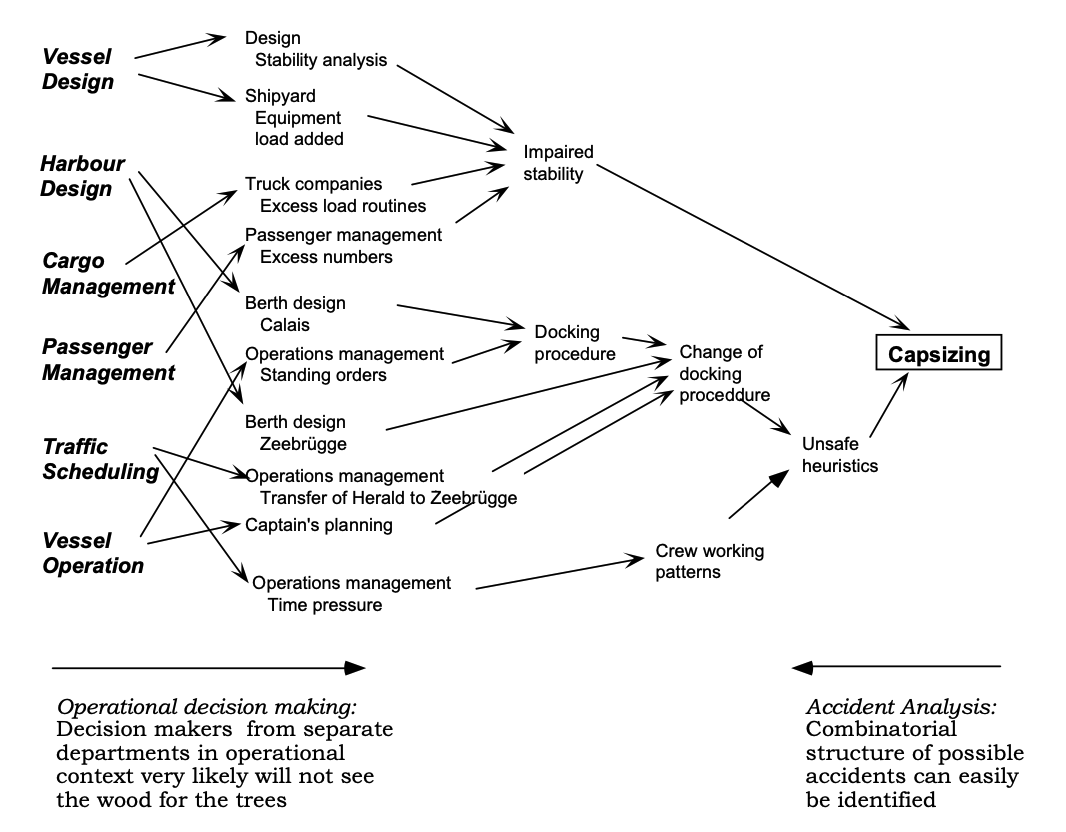
The above figure shows a causal tree derived from the Zeebrügge accident where several decision makers at different times, in different parts of a shipping company, all are striving locally to optimise cost effectiveness and thus are preparing the stage for an accident. The dynamic flow of events can then be released by a single human act.
As seen by the individual decision makers from the front end, it will be difficult to see the total picture during their daily operational decision making. The individual decision makers cannot see the complete picture and judge the state of the multiple defences conditionally depending on decisions taken by other people in other departments and organisations.
A single failure may allow the ship to remain afloat.
But a chain of small failures tied together, form a catastrophic failure. 
The Rasmussen Model, 1997
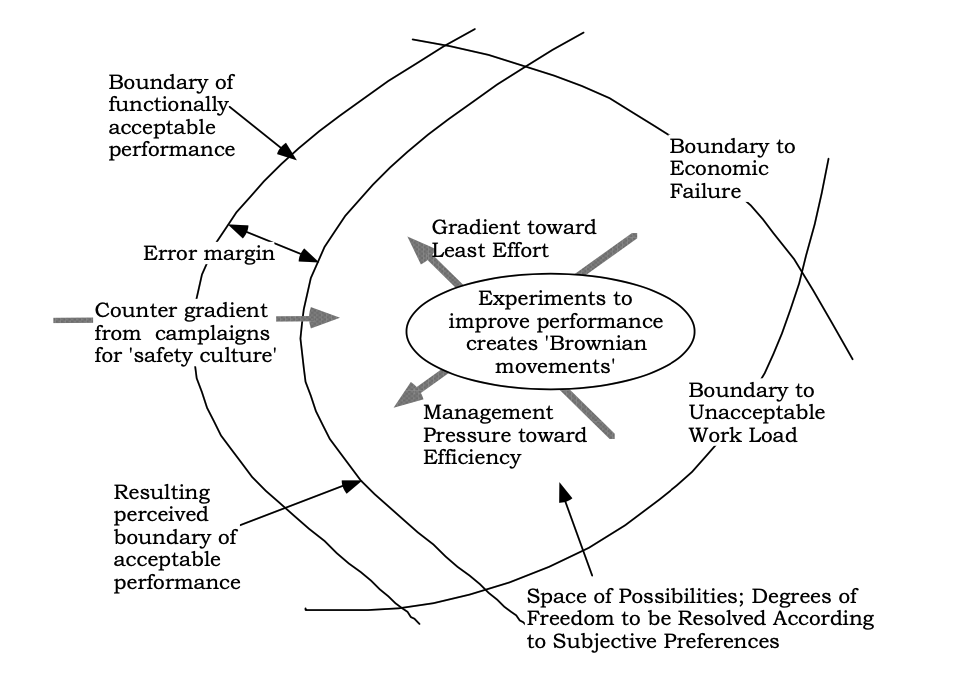
This model helps us understand how systems work and how they are on the edge of safety. There are three boundaries of interest for ay complex system. They are,
- the Economic failure boundary: if the lights are on and the doors are open, your business is running and you must stay within this edge of economic failure boundary. Anything outside leads your business to collapse.
- the Unacceptable workload boundary: this is where your workforce burns out and collapses if they work more than this.
- the Acceptable performance boundary: this can be defined as the mean time between failures or by outages etc. This what we’re to call as acceptable performance for the system. This is also called the Accident boundary.
The space in between these boundaries is where the operating space of your system. The operating point between these boundaries keeps moving as it keeps adjusting to different things. An accident or disaster or outage happens when the operating point moves outide these boundaries.
There are a couple of forces that are constantly acting on the operating point and forcing it specific directions. They are,
- there’s a management pressure for economic efficiency, to push the operating point away from the economic failure boundary. this pressure is stronger the closer your operating point is to the economic failure boundary.
- the closer you are to the unacceptable workload boundary, the stronger is the pressure to push the operating point away from this boundary.
As a consequence, the system is going to be acted on in tandem by both these pressures and push the operating point towards the accident boundary. Left untended, the operating point moves closer and closer to the accident boundary.
If failure is inevitable, what can we do?
There’s only so much you can do to prevent failure. After a point, you hit dimnishing returns. What you can do though, is prepare for failure. You can,
- plan for how to respond to failure
- plan for quick recover
- plan for graceful failure
And that is how you plan for Resiliency. Resiliency sets you apart.We can and should address resiliency in two domains. The People domain and the Technology domain. Each of them are equally important.
Resiliency in the People domain
Here are a few ways I think about resiliency in the people domain,
- talent reviews: knowing where people stand today, knowing where they want to go and helping them get there
- succession planning: do we have too much riding on one person? Is one person irreplaceable because no one else knows what they do? And if that someone cannot be replaced, how do we support their growth?
- organization design: what does this organization/team need to look like next year based on the things we want to accomplish?
- relationships and trust: building relationships and trust in those relationships before you start needing them because it’s hard to build them on demand. When a crisis hits, the last thing you want is a team that does not trust each other and work well with each other.
Resiliency in the Technology domain
Here are a few ways I think about resiliency in the technology domain,
- disaster recovery: designing for DR and executing it regularly
- architecture resiliency patterns: Failover strategies, Data loss prevention strategies, loosely coupled architectures, short release cycles and single responsibility architectures
- failing gracefully: In today’s technical environments there are so many moving parts, so many 99.9% SLAs but put them all in serial, what you experience is far less than 99.9% SLA overall. Ensure your services can continue to function if a few services are down.