Benchmarking, the Whats and the Whys!
TLDR; A benchmark is way to create a point of reference that you can then use to measure other things.
What is a benchmark anyway?
One of the definitions of the word benchmark is that it serves as a point of reference from which measurements may be made. It is important to understand the limits of the system you’ve built and desire to allow customers access to. These limits provide guard rails that define safe conditions for operating our system in production and beyond what range things might start to degrade in performance (or even worse, start falling apart!).
What can you do with a benchmark?
There are several ways to use a benchmark or a set of benchmarks. Some of them are listed below,
- Tuning: You can use a benchmark to identify what is slow and then measure progress as you make changes to optimize it.
- Development: Using a suite of non functional (performance) tests during development would help avoid performance issues (and regressions) from creeping in as we add more code/features. You could also find some of the limits of your system during development and that would help decide where more engineering effort is required to fix/measure some more.
- Capacity Planning: determining system and application limits for capacity planning, to provide data models or for finding these limits directly. If we’re going to add 100,000 new customers, how many new deployements do we need to have? We can answer that once we know how many customers we can support with one deployment, for example.
- Prototyping: In some cases, developing benchmarks with Proof of concepts might be required (or encouraged) before the full product is developed.
Types of benchmarks
Depending on the type of workload they test, there is a spectrum of benchmarks. Micro-benchmarks are at one end of the spectrum, while the other extreme is occupied by Simulation, Replay and Production, in that order.
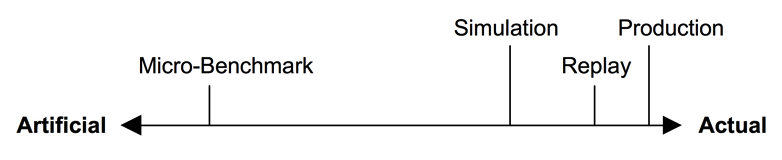
Micro-benchmark
This uses artificial workloads that test a particular type of operation, like performing a single type of file system I/O, database query, CPU operation or system call. By taking a very very narrow and specific view on things, we are able to simplify measurements. This provides us with an easier target to study and allows performance differences to be pinpointed quickly. These benchmarks are also easy to run and are repeatable, because most other variables are held constant and most noise is factored out.
Some examples of this type of benchmark:
- Network: iperf etc
- File system: Bonnie, Bonnie++, SysBench, fio
- CPU: UnixBench, SysBench
Sunny day performance testing, is when you focus on benchmarking with top speeds. Cloudy day performance testing is when you assume operating conditions are less than ideal, where workload is inconsistent, other peturbations occur, contention happens etc.
Simulation
Some benchmarks simulate customer application workloads and may be based on workload characteristics of the production environment. Simulations are also called Macro-benchmarks and can produce results that will resemble how clients will perform with the real-world workload. Simulations could also include effects that may be missed altogether when using micro-benchmarks.
Some examples of this type of benchmark:
- CPU Benchmarks: Whetstone (simulates scientific workloads of time), Dhrystone (simulates integer-based workloads of time.
A workload simulation may or may not be stateful, depending on whether each request made to the server is independent or dependent on previous requests made. One thing to note though, when using simulations is the you need to keep them updated and adjusted to ensure relevancy when customer usage patterns changes.
Replay
This method involves capturing traffic from production for a duration, playing it back against another non production environment (or the environment with the software/hardware you are trying to benchmark), while measuring all the variables that may be of interest.
Industry standards:
These are available from independent companies/organizations which aim to create fair and relevant benchmarks. These could be a collection of micro-benchmarks and workload simulations that are well defined + documented. These save a lot of time as they could possibly be available already for a variety of vendors and products and your task then becomes picking the benchmark that comes closest to your target production environment, rather than running the benchmark itself.
TPC and SPEC are two such organizations that provide benchmarks that can be obtained and used, at a cost. The TPC creates and maintains various industry benchmarks, with a focus on database performance. The SPEC provides a variety of benchmarks, including Cloud/Virtualization ones.
How to measure the right thing and measure it right?
Benchmarking is a non trivial activity, with lots of room for error and also for making outsize returns. Per Smaleders 06, good benchmarks are,
- Repeatable: to facilitate comparisons
- Observable: to facilitat understanding and measuremet of this performance
- Portable: to be able to run on different on products ( even competitor’s)
- Easy to undestand, use now: do that everyone understands the results.
What not to do, when you’re benchmarking:
- Avoid casual benchmarking
- Numbers without Analysis
- Testing the wrong things
- Ignoring errors
- Avoid Benchmark special